📔 csapp chapter02 信息表示与处理 学习笔记
内容和图片截图来源说明¶
- 书籍《深入理解计算机系统》第3版
- 课程PPT:CMU CS15-213
1. 信息的存储¶
大多数计算机使用 8位 的块,或者是字节(byte) ,作为最小的可寻址的内存单元。而不是访问内存中单独的位。
虚拟内存(virtual memory):机器级程序把内存看作一个大的字节数组。
地址(address):内存每一个字节都有唯一的数字标识。所有可能地址的集合叫做虚拟地址空间(virtual address space)。
程序对象(program object):程序数据、指令和控制信息。
1.1 十六进制表示法¶
一个字节 = 8位
十六进制(简写为:hex):以16作为基数,或者叫做十六进制(hexadecimal)数,来表示位模式。
使用数字 0 ~ 9 以及 字符 A ~ F 来表示16个可能的值。

在C语言中,以 0x 或者 0X 开头的数字常量就被认为是十六进制数。
字符 A ~ F ,大小写都可以。
对于十六进制转换为二进制格式,我们可以展开每个十六进制数字,然后转换为二进制格式。
编写机器级程序的一个常见的任务:在位模式 的十进制、二进制和十六进制表示之间人工转换。
例子:将0x173A4C 转换为二进制格式
| 十六进制 | 1 | 7 | 3 | A | 4 | C |
|---|---|---|---|---|---|---|
| 二进制 | 0001 | 0111 | 0011 | 1010 | 0100 | 1100 |
二进制转换为十六进制时,每4位为一组,然后转换为十六进制数。
十进制和十六进制之间的转换¶
较大数值的十进制和十六进制之间的转换,最好是让计算机或者计算器来完成。
最简单的方法:利用任何标准的搜索引擎。
1.2 字数据大小¶
字长(word size):指明指针数据的标称大小(normal size)。
字长决定最重要的系统参数:虚拟空间的最大大小。
如果机器的字长为w,则虚拟地址的范围为 0 ~ 2^w-1,程序最多访问2^w个字节。
大部分数据类型都编码为有符号数值,除非有前缀关键字unsigned或确定大小的数据类型使用了特定的无符号声明。
注意点:char数据类型除外。
1.3 寻址和字节顺序¶
多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
排列表示一个对象的字节有两个通用的规则。

-
大端法(big endian):最高有效字节在最前面的方式
从最低有效字节到最高有效字节的顺序存储(
最低有效字节 ---------> 最高有效字节)。 - 小端法(little endian):最低有效字节在最前面的方式从最高有效字节到最低有效字节的顺序存储(
最高有效字节 ---------> 最低有效字节)。
大多数的Intel兼容机都只是小端模式。
IBM和Oracle的大多数机器则是按大端模式操作。(当然了,它们制造的PC兼容的intel的处理器,也使用到了小端法)
许多比较新的微处理器是双端法(bi-endian),就是配置成大端或小端的机器进行运行。
实际情况下,如果操作系统的确定,那么字节的顺序也随之固定。
目前最常见的Android和IOS系统,都只是运行于小端模式。
对于应用级的程序员来说,机器所使用的字节顺序是不可见的。
字节顺序重要的三种情况: - 在不同类型的机器之间通过网络传送二进制数据时。 - 当阅读表示整数数据的字节序列时,字节顺序也很重要。 - 当编写规避正常的类型系统的程序时(例如C语言的类型系统)。
反编译器(disassemble):是一种确定可执行程序文件所表示的指令序列的工具。
1.4 表示代码¶
机器的指令编码是不同的,不同的机器类型使用不同的且不兼容的指令和编码方式。
由于不同的OS也有不同的编码规则,所以说二进制是不兼容的。(二进制在机器和OS组合的可移植性差)
从机器的角度来说,程序仅仅只是字节序列。
1.5 布尔代数简介¶
二进制值(0和1)是计算机编码、存储和操作信息的核心。
布尔代数(Boolean Algebra):起源于1850钱前后乔治·布尔(George Boole)
通过逻辑值TRUE(真)和FALSE(假)编码为二进制1和0,设计出一种代数,以研究逻辑推理的基本原则。
| 布尔运算符 | 逻辑运算 | 解释 | 集合 |
|---|---|---|---|
~ |
NOT | 非 | 补集 |
& |
AND | 和 | 交集 |
\| |
OR | 或 | 并集 |
^ |
Exclusive-OR | 异或 |

1.5.1 布尔运算的分配率¶
a & (b | c) = (a & b)|(a & c),a | (b & c) = (a | b)&(a | c)
另外,对于 a^a = 0,因此还有 (a ^ b) ^ a = b
1.6 C语言中的位级运算¶
C语言特性之一:支持按位布尔运算。主要用于实现掩码运算。
掩码(一个位模式):表示从一个字中选出的位的集合。
主要有四种:&(与)、|(或)、~(取反)、^(异或)。

位级运算符,适用于任何整型数据类型(long、int、short、char、unsigned)。
1.7 C语言中的逻辑运算¶
逻辑运算符:&&(与)、||(或)、!()。
所有
非零的参数都表示为TRUE,参数 0表示为FALSE。一般情况下,主要返回 0 或 1。会提早终止。
⚠️注意:避免空指针的访问(p && *p)。
1.8 C语言中的移位运算¶
C语言提供了一组移位运算:向左或向右移动位模式。

向左移位¶
x向左移动 k 位,丢弃最高的 k位,并在右端补k个0。
一般来说,机器支持两种形式的右移:逻辑右移 和 算术右移。
- 逻辑右移:在左端补k个0。
- 算术右移:在左端补k个最高有效位的值。
注意点¶
对于无符号数,右移必须是逻辑的。
加减法的优先级高于移位运算符的优先级。
对位运算的说明¶
C语言标准并没有明确定义对于有符号数应该使用哪种类型的右移。
与C相比,java对于右移有明确的定义。
- 表达式x>>K:会将x算术右移k个位置。
- 表达式x>>>k:会对x做逻辑右移。
2. 整数表示¶
用位来编码整数的两种方式: - 表示非负数 - 表示负数、零和正数。
2.1 整型数据类型¶
C语言支持多种整型数据类型------> 表示有限范围的整数。每一种类型都能 使用关键字 来指定大小。也可以指示被表示的数字是非负数或者负数。
在不同的位数(32位或64位)的机器上,取值范围有所不同。(图源来源书籍)
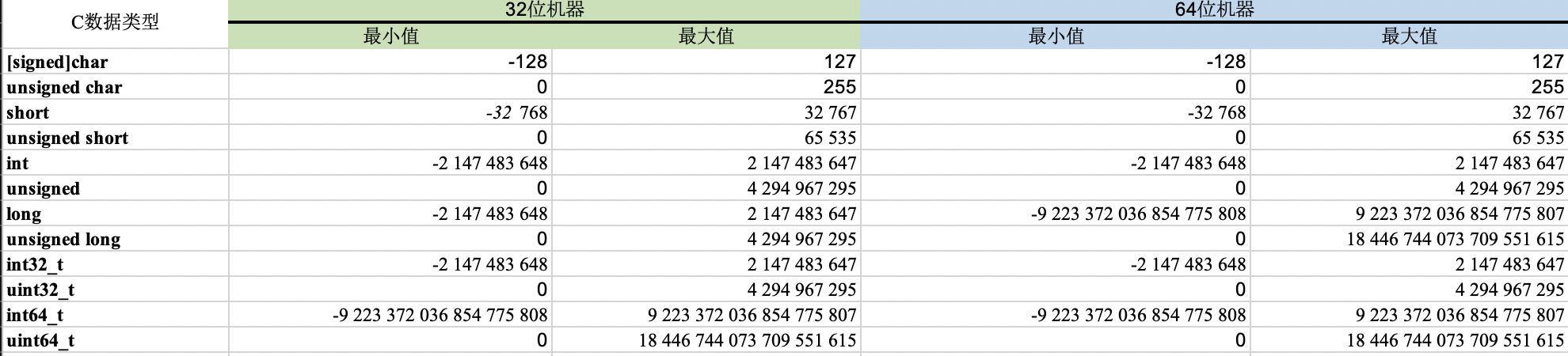
取值范围是不对称的,负数的范围会比正数的范围大1.
C和C++都支持有符号(默认)和无符号数。Java只支持有符号数。
2.2 无符号数的编码¶
定义:
对向量\vec x = [{x_{w - 1}},{x_{w - 2}},\cdots ,{x_0}]:
其中,\vec x 看作一个二进制表示的数,每个位 {x_i} 取值为 0 或 1 。
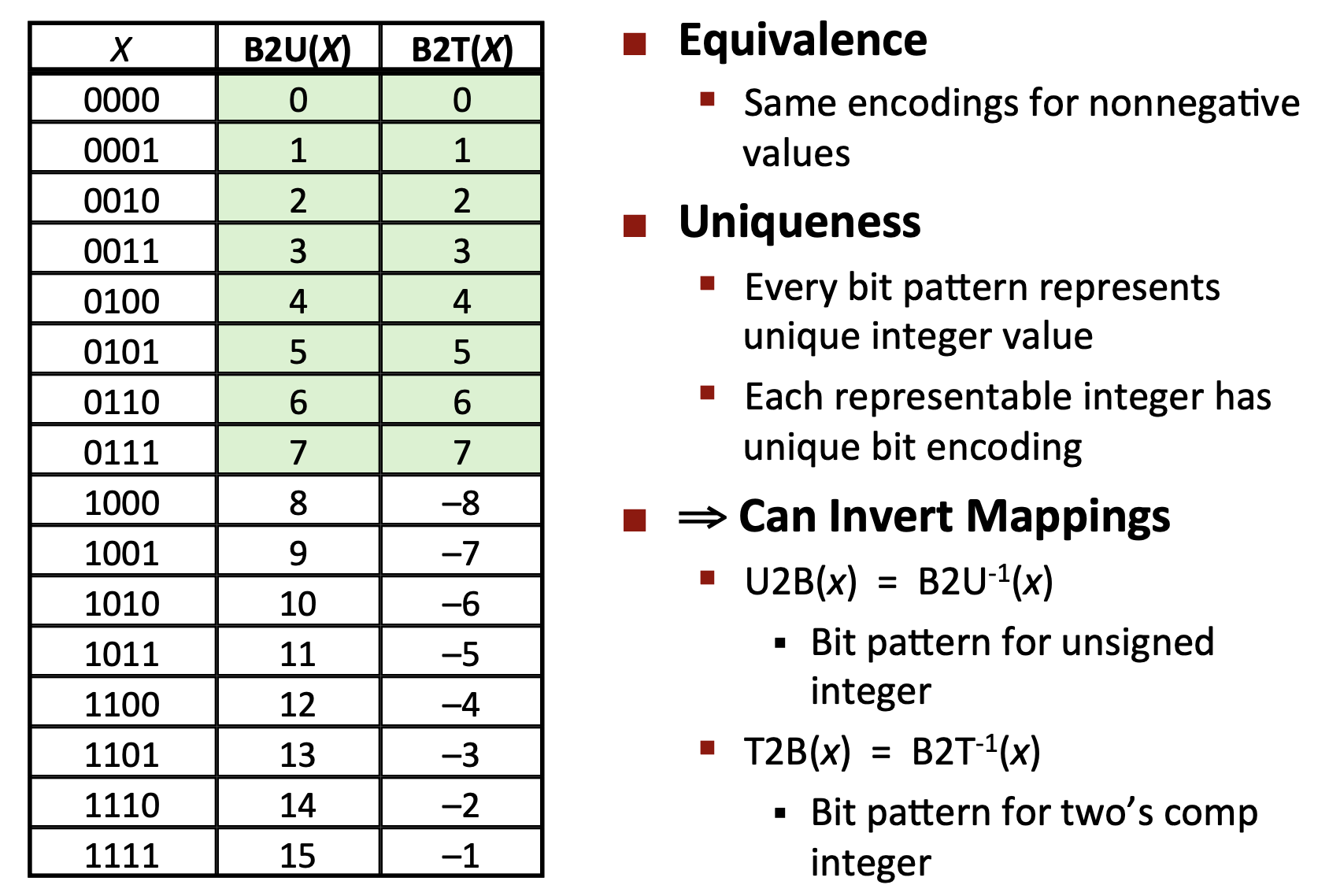
无符号和有符号数值表示
B2U_w(二进制转无符号数)、B2T_w(二进制转补码)
2.3 补码编码¶
因为需要表示负数值而引入。
定义:
对向量 \vec x = [{x_{w - 1}},{x_{w - 2}}, \cdots ,{x_0}]:
最高有效位 {x_{w - 1}} 也称为符号位,它的“权重”为 - {2^{w - 1}},是无符号表示中权重的负数。符号位被设置为1时,表示值为负,而当设置为0时,值为非负。

⚠️注意点:
- 补码的范围是不对称的:\left| {TMin} \right| = \left| {TMax} \right| + 1
TMin没有与之对应的正数。之所以会有这样的不对称性,是因为一半的位模式(符号位设置为1的数)表示负数,而另一半(符号位设置为0的数)表示非负数。因为0是非负数,也就意味着能表示的整数比负数少一个。
- 最大的无符号数值刚好比补码的最大值的两倍大一点:UMa{x_w} = 2TMa{x_w} + 1
补码表示中所有表示负数的位模式在无符号表示中都变成了正数。
C语言标准并不要求一定要用补码形式来表示有符号整数,只是几乎所有的机器在使用。也可以使用其它的形式,如:原码 和 反码。
2.4 无符号数和补码之间的转换¶
在C语言中,是允许各种不同的数字之间进行数据类型之间的强制类型转换。
无符号数与补码之间相互转换的原理:

2.5 C语言中的有符号数和无符号数的转换¶
C语言对有符号数和无符号数表达式的处理方式
当执行一个运算时,如果一个运算数是有符号,而另一个是无符号,那么C语言会
隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。
在C语言中最大值和最小值的写法
2.6 数字扩展和截断¶
2.6.1 数字扩展¶
要将一个无符号数转换为一个更大的数据类型,只要简单地在表示的开头添加0。这种运算被称为 零扩展( zero extension) 。
要将 一个补码数字 转换为 一个更大的数据类型,可以执行一个符号扩展,在最高有效位添加值。

2.6.2 数字截断¶
对于数字扩展是高位添加值,而截断则是从高位丢弃值。但是截断一个数字可能会出现溢出的情况,对于一个无符号数来说,则会容易得出其数值结果。
⚠️注意点:对于补码截断,需要注意将最高位转换为符号位。
2.6.3 扩展和截断基本规则的总结¶

3. 整数运算¶
3.1 无符号加法¶
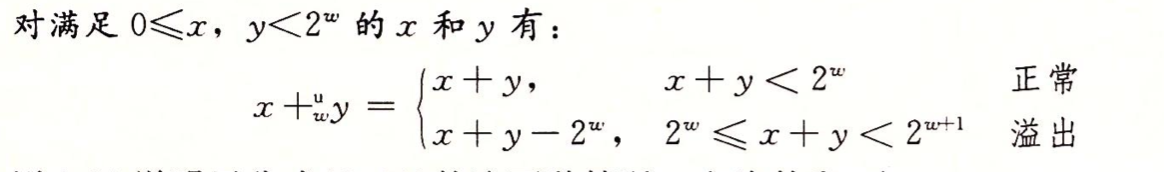
正常情况下,x+y 的值保持不变,而溢出情况则是该和减去 {2^{\rm{w}}} 的结果。
对于算术运算溢出,是指完整的整数结果不能放到数据类型的字长限制中去。
3.2 补码加法¶

两个数的 w位 补码之和与无符号之和有完全相同的位级表示。

3.3 补码的非¶

对 w位的补码加法来说,{TMi{n_w}} 是自己的加法的逆,而对其他任何数值x都有-x作为其加法的逆。
3.4 无符号乘法¶
原理:

3.5 补码乘法¶
原理:

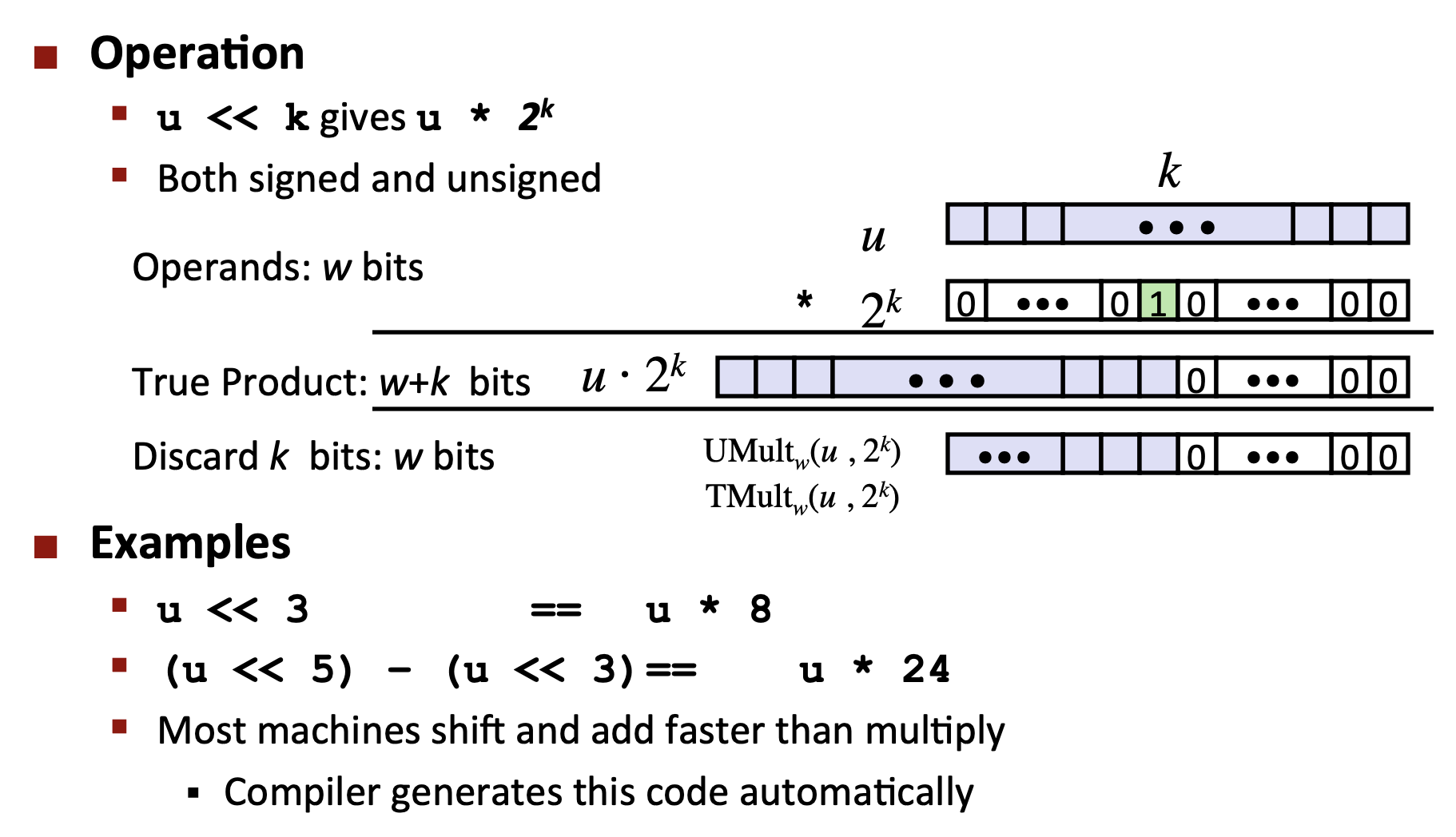
3.6 乘以2的幂¶
在大多数机器上,整数乘法指令相当慢,需要10个或者更多的时钟周期,然而其他整数运算(例如加法、减法、位级运算和移位)只需要1个时钟周期。因此,编译器使用了一项重要的优化,试着用移位(左移)和加法运算的组合来代替乘以常数因子的乘法。
3.6 除以2的幂的无符号除法¶
在大多数机器上,整数除法要比整数乘法更慢(需要30个或者更多的时钟周期)。除以2的幂可以用移位运算(右移)`来实现。

对无符号运算使用移位是非常简单的,部分原因是由于
无符号数的右移一定是逻辑右移。同时注意,移位总是舍入到零。
对于除以2的幂的补码运算来说,情况要稍微复杂一些。首先,为了保证负数仍然为负,移位要执行的是算术右移。
对于x≥0,变量x的最高有效位为0,所以效果与逻辑右移是一样的。因此,对于非负数来说,算术右移k位与除以是一样的。
3.7 算术的基本规则¶

4.浮点数¶
4.1 二进制小数¶

数字权的定义与
十进制小数点符号(.)相关,意味着小数点左边的数字的权是10的正幂,得到整数值,而小数点右边的数字的权是10的负幂,得到小数幂。
4.2 IEEE浮点表示¶
IEEE浮点标准用 V = {( - 1)^s} \times M \times {2^E} 的形式来表示一个数

4.2.1 C语言中浮点数的编码方式¶
-
单精度浮点格式(float):s、exp和frac字段分别为1位、k = 8位和n = 23位,得到一个32位表示。
-
双精度浮点格式(double):s、exp和frac字段分别为1位、k = 11位和n = 52位,得到一个64位表示。

根据exp的值,被编码的值可以分成三种单精度格式的情况:

exp的位模式:既不全为0(数值0),也不全为1(单精度数值为255,双精度数值为2047)。
- 规格化

- 规格化的例子

- 非规格化

- 特殊值

4.3 浮点数的运算¶
- 浮点数的加法
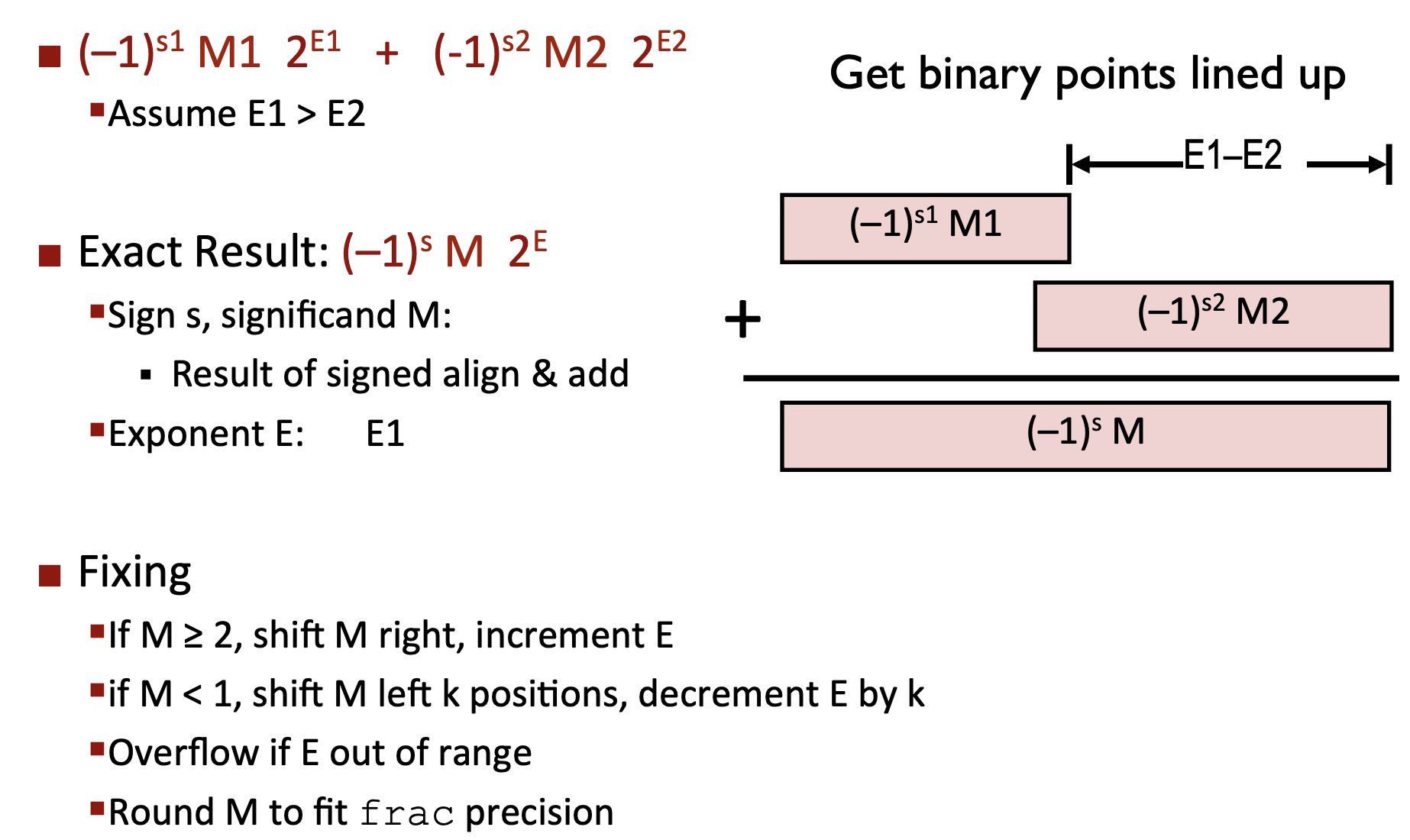
- 浮点数的乘法

4.4 C语言中的浮点数¶

4.5 浮点数的总结¶
