📔 Lecture03 多处理器编程 学习笔记
1. 并发程序的状态机模型¶
对于并发Currency来说 - OS是最早的并发程序之一 - 并发控制算法最早在OS中研究。
1.1 并发的基本单位:线程¶
共享内存的多个执行流 - 执行流拥有独立的堆栈/寄存器。 - 共享全部的内存(指针可以互相引用)。
并发程序的每一步都是不确定性的。
1.2 入门:thread.h简化的线程API¶
-
create(fn) -
创建一个入口函数是fn的线程,并立即开始执行。
void fn(int tid) {...}- 参数tid从1开始编号
-
语义:在状态中新增stack frame 列表并初始化为fn(tid)
-
join() -
等待所有运行线程的fn返回
- 在main返回时会自动等待所有线程结束
-
语义:在有其它线程未执行完时死循环,否则直接返回。
-
编译时需要增加
-lpthread
在整个程序中,如何证明线程确实共享内存?
如何证明线程具有独立堆栈(以及确定它们的范围?)
在创建线程的过程中,可以使用 strace 查看得到是进行了哪一个系统调用。一般情况下,都是直接进行 clone()。当然也可以使用gdb的方式进行。
1.3 POSIX Threads¶
POSIX提供了对应的线程库(pthreads)
- 使用
pthread_create可以直接创建并运行线程 - 使用
pthread_join等待某个线程运行结束。 - 使用
man 7 pthreads可以查看相关的手册。
不管系统是单核还是多核处理器,都可以得到若干个当前进程地址空间的线程。
共享代码:所有线程的代码都来自当前进程的代码。贡献数据:全局数据/堆区可以自由引用。独立堆栈:每个线程都有独立的堆栈。
更多内容后续阅读【多处理器编程的艺术】再次增加笔记内容
2. 原子性¶
2.1 例子:山寨多线程支付宝¶
对于程序来说,两个线程并发执行支付100,会造成什么问题? - 账户里会多出用不完的钱。 - Bug会出现钱的损失。
2.2 例子:求和¶
分两个线程,计算 1 + 1 + 1 + ... + 1(共计2n个1)
-
在程序中可能会出现比N还要小
-
Inline Assembly也不行。
2.3 原子性的丧失¶
程序(甚至一条指令)独占处理器执行的基本假设在现代多处理器系统上不再成立。
原子性:一段代码执行(例如pay())独占整个计算机系统。
-
单处理器多线程
-
线程在运行时可能被中断,切换到另一个线程执行。
-
多处理器多线程
-
线程根本就是并行执行的。
-
(历史)1960s,争先在共享内存上实现
原子性(互斥)。 -
但几乎所有的实现都是错的,直到Dekker's Algothrim,还只能保证两个线程的互斥。
原子性的丧失,会带来很多的问题。但与此同时,互斥和原子性都是两个重要的主题。
- lock(&lk)
-
unlock(&lk)
-
实现临界区(critical section)之间的绝对串行化
-
程序的其它部分依然是可以并行的。
-
对于并发问题,基本上都是可以使用队列的方式解决。

3. 并发程序带来的麻烦¶
3.1 顺序的丧失¶
分两个线程,计算 1 + 1 + 1 + ... + 1(共计2n个1)
对于编译器来说,编译器对内存访问 “eventually consistent”的处理导致了内存作为线程同步工具的失效。
如果要实现源代码的执行时按顺序翻译。那么就可以在代码中插入 “优化不能穿越‘ 的barrier上。可以使用两种方式:
-
asm volatile("" ::: "memory");
-
Barrier 的含义是“可以读写任何内存”。
-
使用volatile变量
-
使用C语义和汇编语义一致.
3.2 可见性的丧失¶
例子:
在现代处理器的角度来说,处理器也是一个动态的编译器。单个处理器把汇编代码编译出更小的ops。

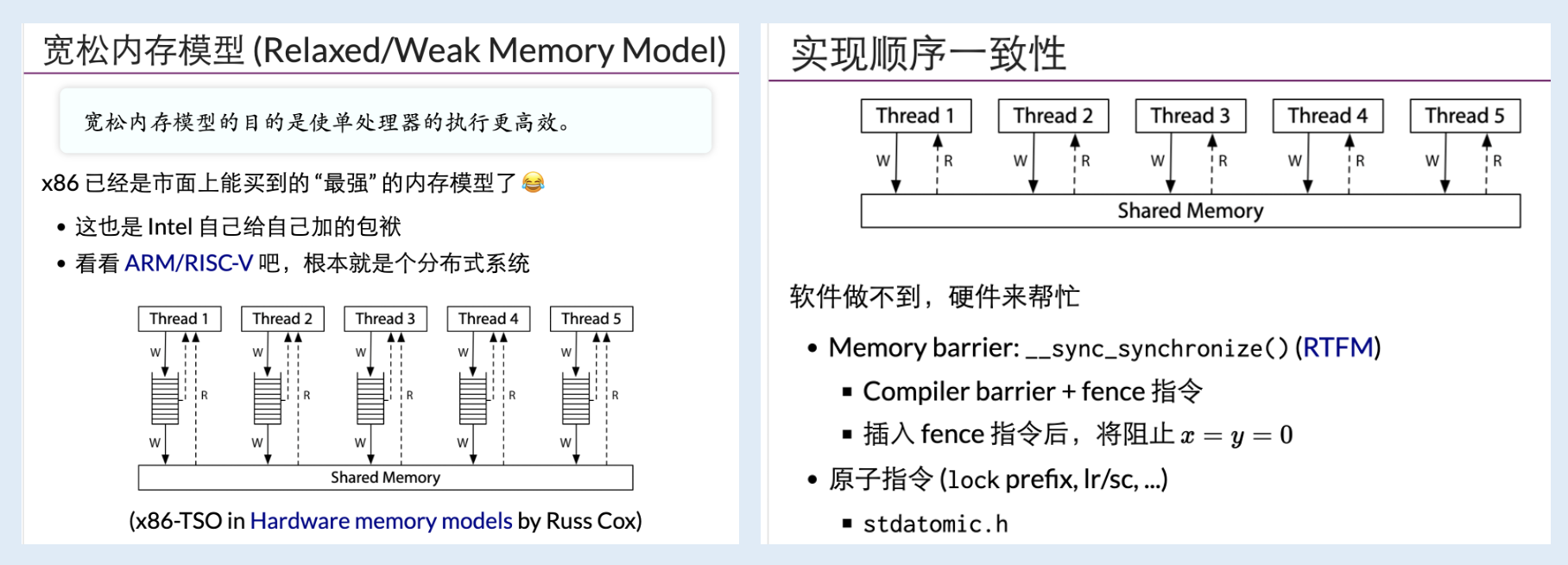
4. 宽松内存模型¶
4. 阅读材料¶
- 《多核处理器编程的艺术》